deeplearning.ai homework:Class 4 Week 1 Convolution model - Application
Convolutional Neural Networks: Application
Welcome to Course 4’s second assignment! In this notebook, you will:
- Implement helper functions that you will use when implementing a TensorFlow model
- Implement a fully functioning ConvNet using TensorFlow
After this assignment you will be able to:
- Build and train a ConvNet in TensorFlow for a classification problem
We assume here that you are already familiar with TensorFlow. If you are not, please refer the TensorFlow Tutorial of the third week of Course 2 (“Improving deep neural networks”).
1.0 - TensorFlow model
In the previous assignment, you built helper functions using numpy to understand the mechanics behind convolutional neural networks. Most practical applications of deep learning today are built using programming frameworks, which have many built-in functions you can simply call.
As usual, we will start by loading in the packages.
1 | import math |
Run the next cell to load the “SIGNS” dataset you are going to use.
1 | # Loading the data (signs) |
As a reminder, the SIGNS dataset is a collection of 6 signs representing numbers from 0 to 5.
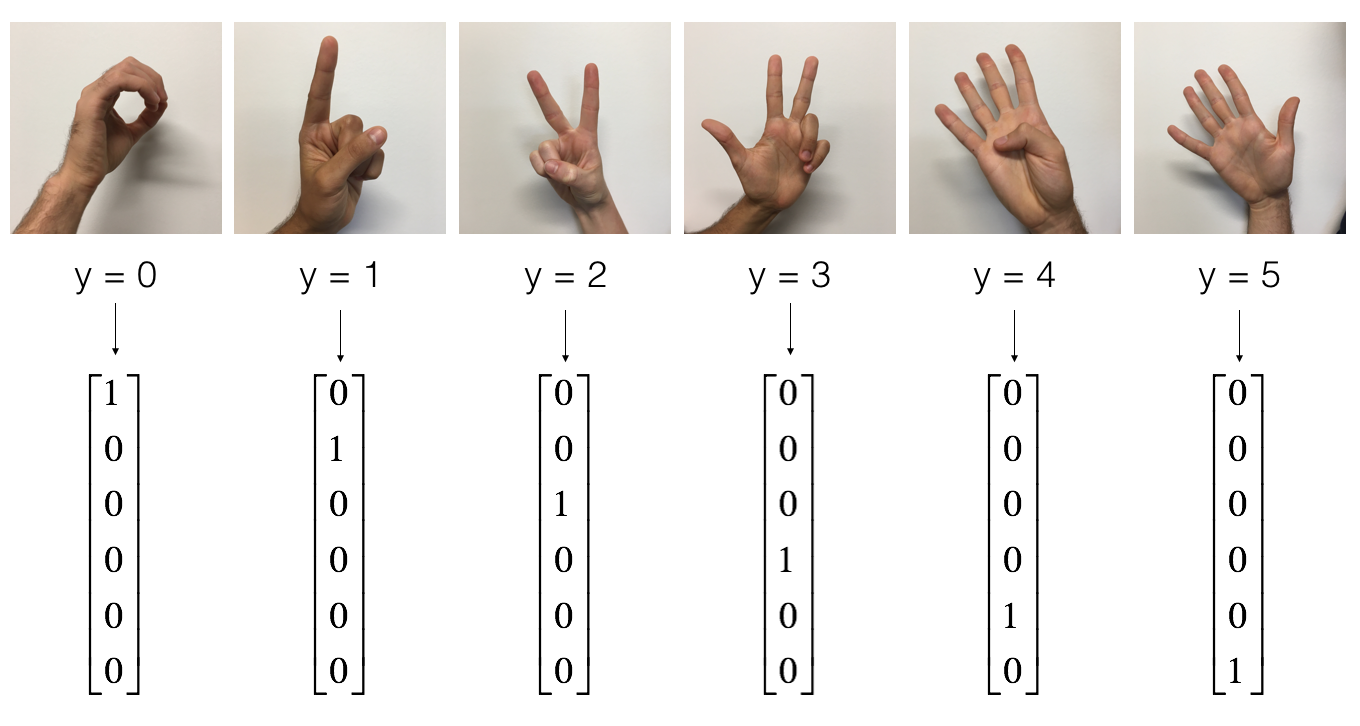
The next cell will show you an example of a labelled image in the dataset. Feel free to change the value of index below and re-run to see different examples.
1 | # Example of a picture |
y = 2

In Course 2, you had built a fully-connected network for this dataset. But since this is an image dataset, it is more natural to apply a ConvNet to it.
To get started, let’s examine the shapes of your data.
1 | X_train = X_train_orig/255. |
number of training examples = 1080
number of test examples = 120
X_train shape: (1080, 64, 64, 3)
Y_train shape: (1080, 6)
X_test shape: (120, 64, 64, 3)
Y_test shape: (120, 6)
1.1 - Create placeholders
TensorFlow requires that you create placeholders for the input data that will be fed into the model when running the session.
Exercise: Implement the function below to create placeholders for the input image X and the output Y. You should not define the number of training examples for the moment. To do so, you could use “None” as the batch size, it will give you the flexibility to choose it later. Hence X should be of dimension [None, n_H0, n_W0, n_C0] and Y should be of dimension [None, n_y]. Hint.
1 | # GRADED FUNCTION: create_placeholders |
1 | X, Y = create_placeholders(64, 64, 3, 6) |
X = Tensor("X:0", shape=(?, 64, 64, 3), dtype=float32)
Y = Tensor("Y:0", shape=(?, 6), dtype=float32)
Expected Output
| X = Tensor("Placeholder:0", shape=(?, 64, 64, 3), dtype=float32) |
| Y = Tensor("Placeholder_1:0", shape=(?, 6), dtype=float32) |
1.2 - Initialize parameters
You will initialize weights/filters and using tf.contrib.layers.xavier_initializer(seed = 0). You don’t need to worry about bias variables as you will soon see that TensorFlow functions take care of the bias. Note also that you will only initialize the weights/filters for the conv2d functions. TensorFlow initializes the layers for the fully connected part automatically. We will talk more about that later in this assignment.
Exercise: Implement initialize_parameters(). The dimensions for each group of filters are provided below. Reminder - to initialize a parameter of shape [1,2,3,4] in Tensorflow, use:
1 | W = tf.get_variable("W", [1,2,3,4], initializer = ...) |
1 | # GRADED FUNCTION: initialize_parameters |
1 | tf.reset_default_graph() |
W1 = [ 0.00131723 0.14176141 -0.04434952 0.09197326 0.14984085 -0.03514394
-0.06847463 0.05245192]
W2 = [-0.08566415 0.17750949 0.11974221 0.16773748 -0.0830943 -0.08058
-0.00577033 -0.14643836 0.24162132 -0.05857408 -0.19055021 0.1345228
-0.22779644 -0.1601823 -0.16117483 -0.10286498]
** Expected Output:**
1.2 - Forward propagation
In TensorFlow, there are built-in functions that carry out the convolution steps for you.
-
tf.nn.conv2d(X,W1, strides = [1,s,s,1], padding = ‘SAME’): given an input and a group of filters , this function convolves ’s filters on X. The third input ([1,f,f,1]) represents the strides for each dimension of the input (m, n_H_prev, n_W_prev, n_C_prev). You can read the full documentation here
-
tf.nn.max_pool(A, ksize = [1,f,f,1], strides = [1,s,s,1], padding = ‘SAME’): given an input A, this function uses a window of size (f, f) and strides of size (s, s) to carry out max pooling over each window. You can read the full documentation here
-
tf.nn.relu(Z1): computes the elementwise ReLU of Z1 (which can be any shape). You can read the full documentation here.
-
tf.contrib.layers.flatten§: given an input P, this function flattens each example into a 1D vector it while maintaining the batch-size. It returns a flattened tensor with shape [batch_size, k]. You can read the full documentation here.
-
tf.contrib.layers.fully_connected(F, num_outputs): given a the flattened input F, it returns the output computed using a fully connected layer. You can read the full documentation here.
In the last function above (tf.contrib.layers.fully_connected), the fully connected layer automatically initializes weights in the graph and keeps on training them as you train the model. Hence, you did not need to initialize those weights when initializing the parameters.
Exercise:
Implement the forward_propagation function below to build the following model: CONV2D -> RELU -> MAXPOOL -> CONV2D -> RELU -> MAXPOOL -> FLATTEN -> FULLYCONNECTED. You should use the functions above.
In detail, we will use the following parameters for all the steps:
- Conv2D: stride 1, padding is “SAME”
- ReLU
- Max pool: Use an 8 by 8 filter size and an 8 by 8 stride, padding is “SAME”
- Conv2D: stride 1, padding is “SAME”
- ReLU
- Max pool: Use a 4 by 4 filter size and a 4 by 4 stride, padding is “SAME”
- Flatten the previous output.
- FULLYCONNECTED (FC) layer: Apply a fully connected layer without an non-linear activation function. Do not call the softmax here. This will result in 6 neurons in the output layer, which then get passed later to a softmax. In TensorFlow, the softmax and cost function are lumped together into a single function, which you’ll call in a different function when computing the cost.
1 | # GRADED FUNCTION: forward_propagation |
1 | tf.reset_default_graph() |
Z3 = [[ 1.44169843 -0.24909666 5.45049906 -0.26189619 -0.20669907 1.36546707]
[ 1.40708458 -0.02573211 5.08928013 -0.48669922 -0.40940708 1.26248586]]
Expected Output:
| Z3 = |
[[-0.44670227 -1.57208765 -1.53049231 -2.31013036 -1.29104376 0.46852064] [-0.17601591 -1.57972014 -1.4737016 -2.61672091 -1.00810647 0.5747785 ]] |
1.3 - Compute cost
Implement the compute cost function below. You might find these two functions helpful:
- tf.nn.softmax_cross_entropy_with_logits(logits = Z3, labels = Y): computes the softmax entropy loss. This function both computes the softmax activation function as well as the resulting loss. You can check the full documentation here.
- tf.reduce_mean: computes the mean of elements across dimensions of a tensor. Use this to sum the losses over all the examples to get the overall cost. You can check the full documentation here.
** Exercise**: Compute the cost below using the function above.
1 | # GRADED FUNCTION: compute_cost |
1 | tf.reset_default_graph() |
cost = 4.66487
Expected Output:
| cost = |
1.4 Model
Finally you will merge the helper functions you implemented above to build a model. You will train it on the SIGNS dataset.
You have implemented random_mini_batches() in the Optimization programming assignment of course 2. Remember that this function returns a list of mini-batches.
Exercise: Complete the function below.
The model below should:
- create placeholders
- initialize parameters
- forward propagate
- compute the cost
- create an optimizer
Finally you will create a session and run a for loop for num_epochs, get the mini-batches, and then for each mini-batch you will optimize the function. Hint for initializing the variables
1 | # GRADED FUNCTION: model |
Run the following cell to train your model for 100 epochs. Check if your cost after epoch 0 and 5 matches our output. If not, stop the cell and go back to your code!
1 | _, _, parameters = model(X_train, Y_train, X_test, Y_test) |
Cost after epoch 0: 1.921332
Cost after epoch 5: 1.904156
Cost after epoch 10: 1.904309
Cost after epoch 15: 1.904477
Cost after epoch 20: 1.901876
Cost after epoch 25: 1.784077
Cost after epoch 30: 1.681051
Cost after epoch 35: 1.618206
Cost after epoch 40: 1.597971
Cost after epoch 45: 1.566707
Cost after epoch 50: 1.554487
Cost after epoch 55: 1.502188
Cost after epoch 60: 1.461036
Cost after epoch 65: 1.304490
Cost after epoch 70: 1.197038
Cost after epoch 75: 1.144872
Cost after epoch 80: 1.098986
Cost after epoch 85: 1.089278
Cost after epoch 90: 1.039330
Cost after epoch 95: 1.004071
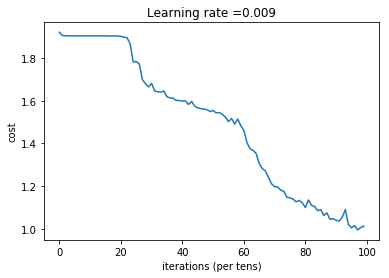
Tensor("Mean_1:0", shape=(), dtype=float32)
Train Accuracy: 0.662037
Test Accuracy: 0.55
Expected output: although it may not match perfectly, your expected output should be close to ours and your cost value should decrease.
| Cost after epoch 0 = |
| Cost after epoch 5 = |
| Train Accuracy = |
| Test Accuracy = |
Congratulations! You have finised the assignment and built a model that recognizes SIGN language with almost 80% accuracy on the test set. If you wish, feel free to play around with this dataset further. You can actually improve its accuracy by spending more time tuning the hyperparameters, or using regularization (as this model clearly has a high variance).
